

Keep Up With Current Events
Scottge delivers recent news from various categories, highlighting notable developments across different areas.
new Shaping Daily Life
From business to home and living, Scottge shares information that reflects events affecting everyday life.
Explore a Variety of Topics
Scottge provides news across different categories to keep readers informed about the world around them.
Follow the Latest News
Stay informed on current events across all categories with Scottge.
Timely Business Updates
Stay informed with the latest developments and news in business and related areas on Scottge.
Technology News Highlights
Follow the latest updates and news in technology and related fields on Scottge.
Health News Updates
Stay informed on recent developments and events in health and wellness topics through Scottge.
Access the latest news and updates across all categories available on Scottge.
Comprehensive News Coverage
Scottge provides up-to-date news and information across multiple categories.
Current Events Updates
Follow important events and breaking news from around the world.
Business News
Stay informed on recent developments in business and finance.
Health and Lifestyle Updates
Keep track of the latest news in health, home, and pet topics.
Technology and Entertainment News
Access current updates on technology, gadgets, and entertainment trends.








Latest news

Discover briliantz gel blasters: your ultimate outdoor adventure
Briliantz gel blasters redefine outdoor play with innovative design and unmatched[…]
Comment Réussir un Pain Maison Croquant en 2026 ?
Comment réussir un pain maison croquant ? Les clés pour un[…]
Comment Utiliser un Wok Efficacement en 2026 ?
Comment bien utiliser un wok pour cuisiner facilement en 2026 ?[…]
Quel est le Meilleur Guide pour le Choix de Couteaux de Chef Débutant en 2026 ?
Le guide complet pour bien choisir son couteau de chef quand[…]
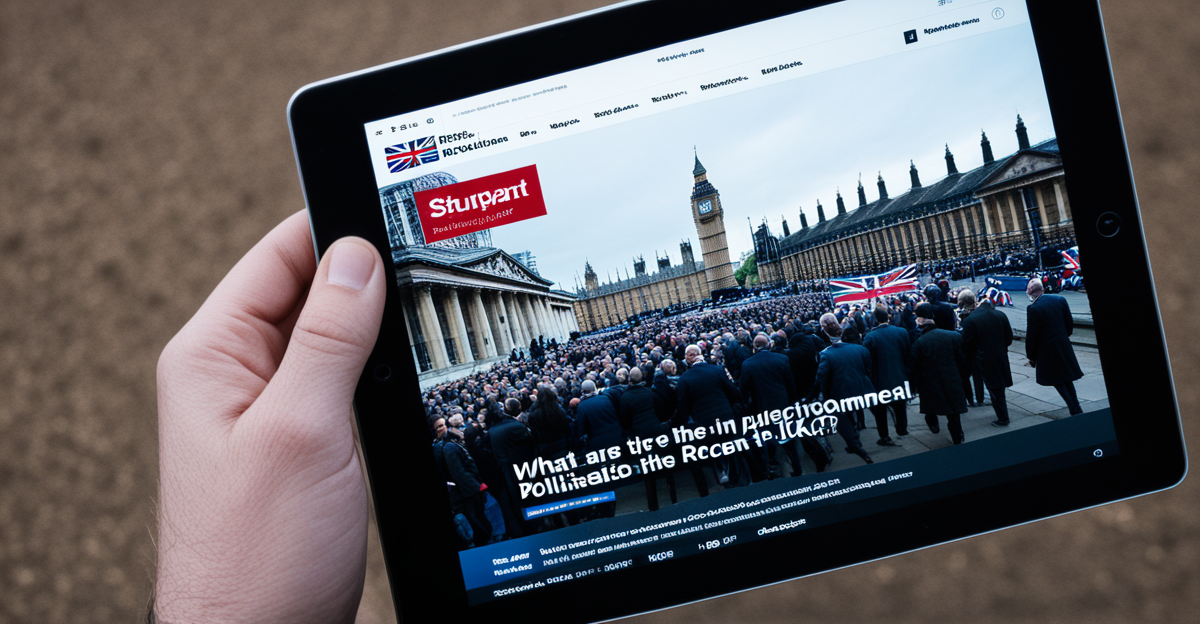
What Are the Latest Political Developments in the UK?
Recent Political Events Shaping the UK Landscape Recent weeks have seen[…]

Brexit’s Impact on the UK Economy: What Are the Long-Term Consequences?
Long-Term Shifts in UK Trade Relations Understanding the long-term shifts in[…]

What influence do UK tabloids have on public opinion?
Influence of UK Tabloids on Shaping Public Opinion UK tabloids wield[…]

Briliantz gel blasters: quality fun for outdoor enthusiasts
Briliantz gel blasters combine innovative design with reliable performance, making them[…]