Marketing and Technology Blog
Combine marketing and technology to grow your online presence
Blogging
Digital Marketing
Digital Marketing
Linkedin Growth
Discover easy, actionable strategies to boost your LinkedIn visibility and networking without extensive writing or messaging
Blogging
Essential List of Web Development Tools
Websites are the most important real estate on the internet. This essential list of web development tools will help you to organize your work with websites.
Digital Marketing
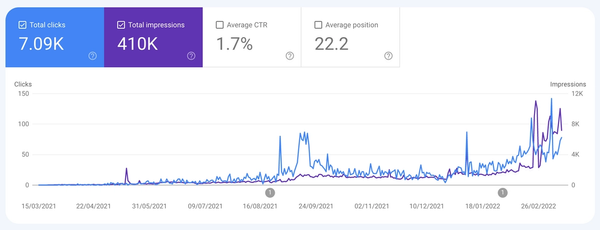
How Google Indexing Works (Definitive Guide for SEO)
This Guide will answer many questions about Google indexing. After reading this guide you will be able to make better decisions when writing content.
Blogging
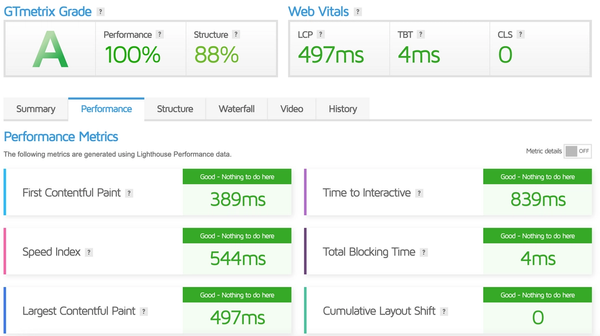
Why website speed is important
Why is website speed important? This guide will list the reasons only why website speed is important and will help to improve your website's speed.
Digital Marketing
Facebook Ad Targeting
There is no faster way to get traffic than with paid ads. Facebook has a record number of users, and it has a lot of targeting options that advertisers can use.
Digital Marketing
Domain Authority and Domain Rating
What are Domain Authority and Domain Rating and why are they important for your websites
Blogging
How Modern Technologies Change The Web Development
If you have a website or plan to have one then this guide will help you on the technology or agency selection process
Blogging
Image Reverse Search
Explore the power of reverse image search: a simple yet effective tool to enhance your online visibility.
Digital Marketing
Top 10 Websites in the World 2022 and How They Get Their Traffic
How the world's top websites get their traffic. This analysis will help you to plan your marketing budget
Digital Marketing
Finding Keywords for Search Engine Optimization
Finding keywords for SEO is an important part of the blog post writing process. It will help you to get more traffic for your articles.
Blogging
How To Start Your Blog and Host For FREE
When starting a blog, it is important to pick a correct platform to facilitate the blog's growth.
Blogging
Image SEO Optimization
Optimizing images in your blog posts will help you get more traffic from search engines. Learn how you can optimize images for your next blog post.
Digital Marketing
Groundwork for SEO
When you are planning to start a new website, this guide will help you make correct SEO decisions.